지난 글에서 토큰 비용은 우회할 변수가 아니라 설계에 넣어야 할 상수라고 했다.
그럼 어떻게 재나.
대부분은 안 잰다. 청구서가 와야 안다. 그러면 이미 늦었다.
토큰 비용을 본다는 건 사용량을 확인하는 일이 아니다. 어떤 작업이, 어디서, 왜 비용을 만들었는지 실시간으로 아는 일이다.
재는 건 어렵지 않다. 두 가지만 정하면 된다. 어디서 계측할지, 무엇을 볼지.
어디서 계측하나
제일 쉬운 건 게이트웨이다. 모든 LLM 호출을 한 곳으로 통과시키고 거기서 토큰을 잰다. 코드는 거의 안 건드린다 — 엔드포인트나 헤더 한 줄. 붙이기 쉬운 대신 작업 단위로 깊게 쪼개 보기는 약하다. 개인이나 초기 팀에 맞는다. LiteLLM, Portkey, Helicone 같은 게 이 방식이다.
더 깊게 보려면 트레이싱을 앱에 심는다. Langfuse 같은 도구가 호출 하나하나, 단계 하나하나를 따라가며 기록한다. 에이전트를 단계별로 뜯어볼 수 있는 대신 관측 데이터가 빨리 쌓인다. 팀·서비스 운영에 맞는다.
세 번째는 직접 쌓는 것이다. 호출 기록을 내 DB에 직접 적는다. 손이 가는 대신 원하는 기준으로 비용을 자른다. 뒤에서 따로 다룬다.
이미 Datadog 같은 모니터링을 쓰고 있으면, 거기 LLM 탭을 켜는 게 제일 빠르다.
도구 지형은 자주 바뀐다. 인수되거나, 가격 정책이 달라지거나, 무료 한도가 바뀐니, 도입 전엔 가격·데이터 보관 방식·제품 지속성을 한 번 확인하는 게 좋다.
무엇을 보나
도구보다 이게 중요하다. 그리고 핵심은 하나다.
토큰 수 자체는 별 의미가 없다. 중요한 건 작업 하나가 얼마짜리인지다.
이메일 한 통 요약, 보고서 한 편 작성, 에이전트 실행 한 번. 그게 각각 얼마인지 알아야 설계가 가능하다. 그래서 보는 항목도 “작업당”으로 모인다.
- 작업당 비용 — raw 토큰 말고 작업 하나당, 성공 하나당 비용. LLM은 같은 일도 매번 다르니 평균만 보면 안 된다. p95까지 본다.
- 귀속 — 호출마다 어느 작업·기능·사용자인지 꼬리표를 단다. 그래야 어디서 새는지가 보인다.
- 트레이스 — 에이전트는 한 작업에 여러 번 부르니까, 작업 하나를 통째로 따라가며 어느 단계가 토큰을 먹는지 본다.
- 한도와 알림 — 키별·기간별 한도를 걸고 넘으면 알림. “청구서 와야 안다”의 해법이다. 사후가 아니라 실시간.
보고 끝이 아니다. 보면 고칠 게 보인다.
- 출력 토큰이 갑자기 늘었다 → 프롬프트가 장황해졌거나 요약이 실패했거나.
- 특정 단계 비용이 높다 → 그 단계만 작은 모델로 내리거나 캐시 후보.
- 실패한 작업의 비용이 높다 → 재시도·타임아웃·라우팅을 손볼 때.
- 작업당 비용은 낮은데 성공률이 낮다 → 비용 문제가 아니라 품질 문제.
표준도 하나. OpenTelemetry GenAI 규약에 맞춰 기록하면 벤더에 안 묶여서 도구를 갈아끼우기 쉽다.
직접 깔아보면
예로 Langfuse를 깔아보자. 오픈소스고, 에이전트 한 작업이 토큰을 어디서 먹는지 단계별로 보여줘서 시작점으로 좋다.
두 가지 길이 있다. 클라우드는 가입하면 끝이고, 지금 기준 무료 티어로 실험해보기 좋다(한도·가격은 바뀔 수 있다). 내 데이터를 내 서버에 두고 싶으면 Docker로 직접 띄운다 — docker compose up 한 번이면 여섯 개 컨테이너가 같이 뜬다. 다만 그중 ClickHouse가 끼어 있어 손이 좀 가니, 혼자 쓰는 거면 클라우드가 훨씬 편하다.
붙이는 건 더 간단하다. import 한 줄을 바꾼다.
from langfuse.openai import openai
그러면 그다음 모든 호출이 토큰·비용·지연과 함께 대시보드에 쌓인다. 함수를 통째로 추적하려면 @observe()를 붙인다. 그 안의 호출들이 부모-자식 스팬으로 묶인다.
대시보드에서 보이는 것:
- 호출마다 — 모델, 입력·출력 토큰, 비용, 지연이 한 줄로.
- 트레이스 트리 — 에이전트 한 작업을 펼치면 단계가 스팬으로 쌓인다. 어느 단계가 토큰을 먹는지 한눈에 보인다. (앞 글의 1→N→M·N이 여기서 실제 숫자로 보인다.)
- 토큰 추세 — 시간에 따른 토큰 그래프. 어느 날 갑자기 튀면, 프롬프트가 바뀌었거나 출력이 길어진 버그라는 신호다.
- 원하면 비용 옆에 품질 점수까지.
주의 하나. 에이전트는 한 작업에 관측이 5~10개씩 붙어서 무료 한도를 생각보다 빨리 쓴다. 그만큼 볼 게 많다는 뜻이기도 하고.
직접 쌓는 길
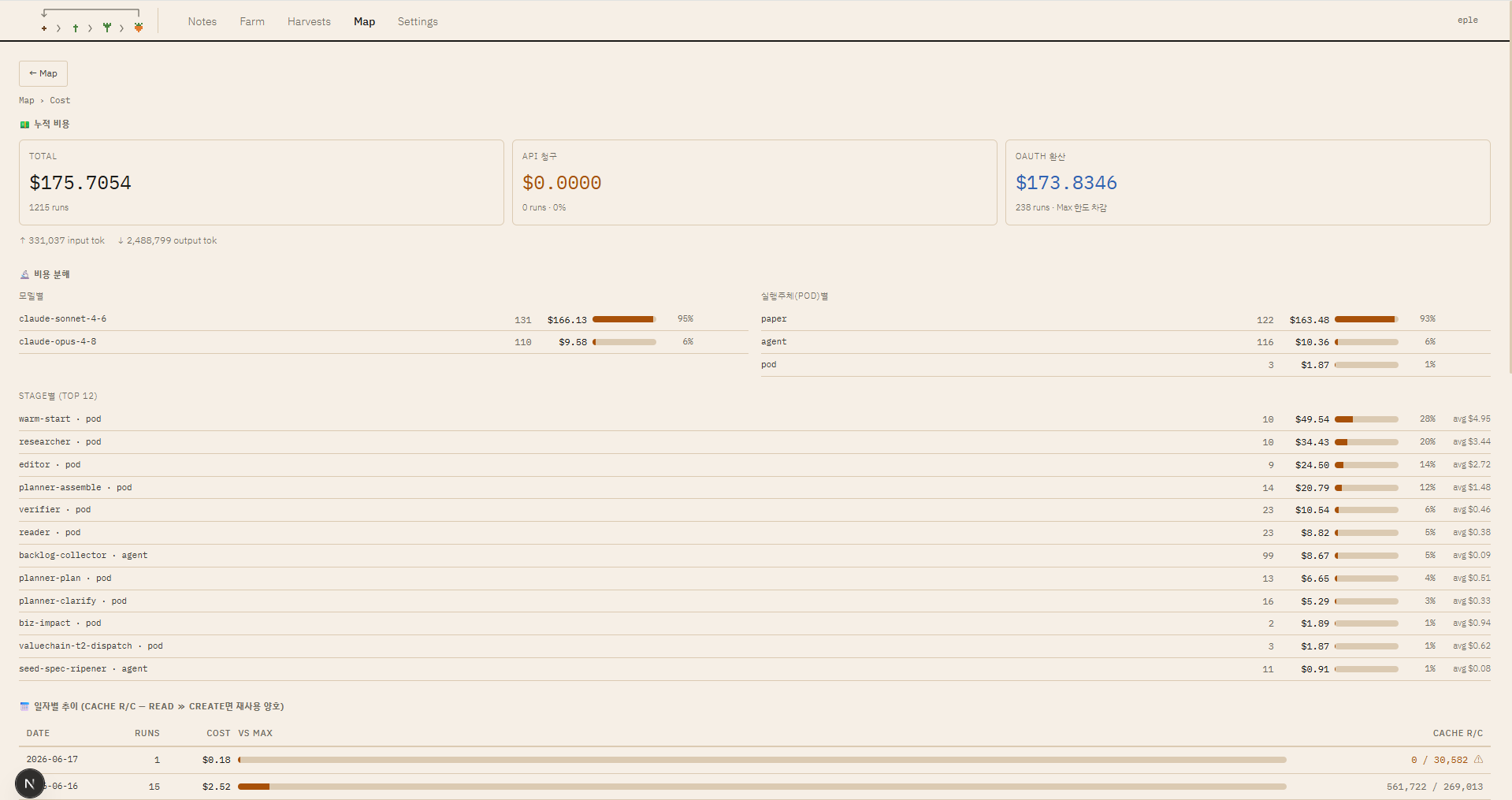
사실 나는 이 방법을 쓴다.
도구를 붙이는 대신, 파이프라인이 도는 매 단계의 토큰과 비용을 내 DB에 직접 쌓는다. 행 하나에 이런 걸 적는다.
task_id 작업 IDstep 단계 (요약·검색·작성·검토…)model 모델input_tokens 입력 토큰output_tokens 출력 토큰cached_tokens 캐시 토큰cost_usd 비용billing_type 실청구 / 구독 추정success 성공 여부latency_ms 지연
별것 아니다. 테이블 하나면 된다.
그러면 작업 하나당 비용이 쿼리 한 줄로 나온다.
글 한 편 만드는 데 얼마가 들었는지, 어느 단계가 토큰을 제일 먹는지가 보인다.
앞에서 본 트레이스 트리를, 작은 테이블 하나로 직접 만든 셈이다.
Claude Code를 쓴다면 더 쉽다. 로그를 직접 파싱할 필요도 없다.
환경변수 세팅하면 OpenTelemetry로 토큰·비용·세션을 수집할 수 있다.
CLAUDE_CODE_ENABLE_TELEMETRY=1
이벤트마다 붙는 prompt.id로 “이 작업 하나가 토큰을 얼마나 사용했는가가 봉이고,
그걸 수집기에서 내 DB로 떨어뜨리면 끝이다.
내 서버에 쌓이고, 종량 과금도 없고, 원하는 대로 쿼리한다.
대신 대시보드와 알림은 내가 짠다. 조건은 몇 개면 된다 — 어제 비용이 일주일 평균의 두 배를 넘으면, 특정 작업의 p95 비용이 기준을 넘으면, 실패한 작업의 누적 비용이 일정 선을 넘으면. 사후가 아니라, 튀는 그날 안다.
도구를 빌릴 것인가, 직접 소유할 것인가. 나는 후자를 골랐다. (Claude Code 공식 문서)
아마도 그래서 부족할 점들은 쓰면서 계속 개선해야겠지,
그래서
혼자 쓰는 거면 복잡하게 안 해도 된다. 게이트웨이 하나에 한도·알림만 걸어도 충분하다.
팀이면 트레이싱과 품질 평가까지 붙이는 것이 좋을 것 같다.
비용 옆에 “그래서 결과가 좋았나”를 같이 봐야 하니까.
핵심은 도구가 아니다. 사후가 아니라 실시간에 본다는 것.
비용을 본다는 건 아끼자는 뜻이 아니라, 토큰 청구서가 오기 전에 설계를 통제하자는 뜻이다.

“토큰 청구서가 오기 전에 — 비용을 보는 법” 글에 댓글 1개
[…] 토큰 청구서가 오기 전에 — 비용을 보는 법 […]